11.7 變異數分析ANOVA1
單向變異分析(ANOVA1)旨在尋找不同類別下之資料是否具有相同均值,亦即決定不同類別下,各量測值是否具有差異特性。在線性模式下,單向變異分析是最簡單的狀況。任何量測值可以矩陣表示如下:
yij = αjεij
其中,yij中每行j代表不同類別,並具有類別內之平均值 。在工具箱中存有hogg.mat資料,下載後可以作為執行anova1函數之用,其過程如下:
>> load hogg
>> hogg
hogg =
24 14 11 7 19
15 7 9 7 24
21 12 7 4 19
27 17 13 7 15
33 14 12 12 10
23 16 18 18 20
ANOVA指令之型式如下:
P = ANOVA1(X,GROUP,DISPLAYOPT)
此指令會將X組合之樣本矩陣中之各行視為比較之組別,以此決定組別間之平均值是否會相等。GROUP為分組向量,其長度應與X之行數相同,其內容即為各組之名稱。指令左邊為結果之機率,其值愈小表示相等之機率愈小,亦即顯著性之差異愈大。GROUP向量可以容許使用字串或細胞陣列,但必須以行表示。若不使用組別名稱則可以空格。
DISPLAYOPT為顯示開關,可用 'on' (預設值)或 'off'決定是否顯示結果圖。若要文字輸出ANOVA表,則可在左邊加一參數如ANOVATAB:
[P,ANOVATAB, stats] = ANOVA1(...)
參數ANOVATAB為細胞陣列,stats則為一些統計參數。
例:
>> [p,tbl,stats]=anova1(hogg)
p =
0.00011971
tbl =
'Source' 'SS' 'df' 'MS' 'F' 'Prob>F'
'Columns' [ 803] [ 4] [200.75] [9.0076] [0.00011971]
'Error' [557.17] [25] [22.287] [] []
'Total' [1360.2] [29] [] [] []
stats =
gnames: [5x1 char]
n: [6 6 6 6 6]
source: 'anova1'
means: [23.833 13.333 11.667 9.1667 17.833]
df: 25
s: 4.7209

在本例中,hogg之資料實際上各行代表不同處理之細菌繁殖情形。利用ANOVA變異分析表之結果亦可做 F-test,以證明不同處理是否仍然具有相同的結果。此例所得之p值約為 0.0001,這是一個相當小的值。換句話說,此種結果強烈顯示不同的處理其結果之差異是顯著的。若就或然率考慮,每10,000次實驗當中只有一次有結果相同的機會。對於研究者而言,這是一個很大的鼓舞,因為至少由統計分析結果可證明:不同處理比較下,應有很大的差異性的。當然,上述p值要正確,其基本假設是各項變異應獨立,且屬常態分配,其變異值也是固定。這些差異性由圖也可以看出端倪。
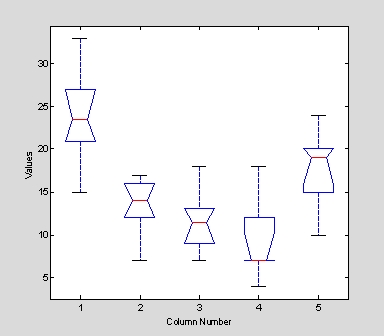
上述之指令,若要加上各行之名稱,則可另以如下之指令為之:
>> [p,tbl,stats]=anova1(hogg,{'A1','A2','A3','A4','A5'}')
其執行結果與前述無異,但在最後之組別圖中會出現分組之組名。
沒有留言:
張貼留言