11.7.2雙變異分析
單變異與雙變異分析上不同的地方是後者具有兩組類別,其所定義的特性不相同。例如某汽車公司有兩家工廠,每家工廠均生產相同的三車種。此時生產之汽車之里程數作合理的比較時,其差異可能有兩項:其一是甲乙兩工廠間之差異,其二是車型間之差異。 此時工廠別與車型別兩者均會影響汽車之里程數。其間差異可能來自工廠間之製造,也可能是因車種設計或規格上的問題,後者之問題可能與工廠無關。 此外,某工廠也可能對生產某一車種有獨到的製造能力(可能因為有較佳的生產線吧!),卻製造其他車種則與另一工廠不相上下,這種效應稱為加減性,或兩項類別間之交互作用所產生之影響。
雙變異分析(ANOVA)是線性模式之特殊狀況。就汽車之里程數可以表示如下:
yijk=μ+α.j+βi.+γij+εijk
其中,yijk為里程數之觀察資料(列指標為i,行指標為j,重複標為k)。μ整個矩陣之平均值。α.j為由於車型j與μ差異之均值,βi.則是工廠別i與μ差異之均值,γij為交互作用項,其在行向之和或列向之和為零。εijk 為整個隨機之變異量。
由上述汽車之製造例可知,其觀察之里程數變成一種矩陣的型式,具有j行與i列的組別項,此時由行與列構成之組別或稱為處理(Treatment),對應於行列方向之交叉點即為細胞(Cell),每個細胞位置必須重複置放樣本觀察數,或稱為重複數( repetition)。若以矩陣表示,此重複數必須置於k方向。
ANOVA2為分析雙變異數之指令。其格式如下:
ANOVA2(X, REPS, DISPLAYOPT)
輸入參數X為觀察之資料矩陣,其行與列均需二項以上,以作為比較之基準。在各行的資料代表一類別;各列者則為另一類別。若每一對應細胞有多個觀察資料,則由REPS指定。若REPS=3,代表每個細胞位置有三筆資料,這些資料依列之類別依序置於列中。因此若REPS=3,則在列中每三筆資料屬其中一組,下三筆屬第二組,如此類推,其總列數因而應為三(REPS)的倍數。另外參數DISPLAYOPT之定義與前述指令之用法相同。
輸出參數則表示如下:
[P, TABLE, stats] = ANOVA2(...)
其中 P為p值之向量,而 TABLE則為細胞陣列,包括ANOVA表的內容。stats則為分析後之統計資料,可以作為其他指令如MULTCOMPARE函數之輸入。
若有非平衡變異資料則可採用ANOVAN指令進行分析,詳細情形可以參考手冊或輔助資料。
茲以工具箱中存有mileage.mat之車型生產資料為例,可以作為本節之分析示範:
>>load mileage
>>mileage
mileage =
33.3 34.5 37.4
33.4 34.8 36.8
32.9 33.8 37.6
32.6 33.4 36.6
32.5 33.7 37
33 33.9 36.7
此為三種車型(行)及二家工廠製造之汽車每加侖里程資料,其reps=3,故第1-3列代表第一家工廠製造之車輛,第4-6列代表第二家工廠。將相關參數代入anova2指令,可得結果為:
>>[p,tbl,stats] = anova2(mileage,3)
p =
2.4278e-010 0.0039095 0.84106
tbl =
'Source' 'SS' 'df' 'MS' 'F' 'Prob>F'
'Columns' [53.351] [ 2] [ 26.676] [ 234.22] [2.4278e-010]
'Rows' [ 1.445] [ 1] [ 1.445] [ 12.688] [ 0.0039095]
'Interaction' [ 0.04] [ 2] [ 0.02] [0.17561] [ 0.84106]
'Error' [1.3667] [12] [0.11389] [] []
'Total' [56.203] [17] [] [] []
stats =
source: 'anova2'
sigmasq: 0.11389
colmeans: [32.95 34.017 37.017]
coln: 6
rowmeans: [34.944 34.378]
rown: 9
inter: 1
pval: 0.84106
df: 12
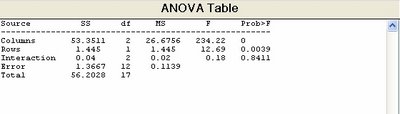
除文字及統計數據外,尚有一個標準的 ANOVA表,其中第一行為行,其平方和(SS)、自由度(df)及均方值 (MS=SS/df), F 檢定及或然率 p-值等。 F檢定可以檢驗車型間、工廠間及車型X工廠之交互作用(經過調整後之增加效應)產生之里程數是否相同。由於 p-值在車型間之效應幾乎近於零(至小數四位),表示車型對里程數之變異甚大,有顯著之影響。經由 F檢定結果,因車型而發生同平均值之情況,其機率為萬分之一。若使用MULTCOMPARE指令比較:
>>COMPARISON = MULTCOMPARE(stats)
Note: Your model includes an interaction term. A test of main
effects can be difficult to interpret when the model includes
interactions.
COMPARISON =
1 2 -1.5865 -1.0667 -0.54686
1 3 -4.5865 -4.0667 -3.5469
2 3 -3.5198 -3 -2.4802
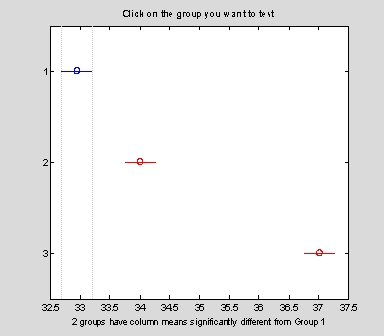
利用multcompare函數比較結果,三車型之差異有明顯之不同。而 p-值對工廠間之機率值為 0.0039,這也是一個非常顯著之差異。顯然,某一工廠製造的汽車,其里程數是比另一廠為高。由其 p-值得知,只有千分之四的機率兩工廠製造的汽車之里程數才會相同。就工廠X車型間交互作用之影響而言,則不顯著。其 p-值僅 0.8411,亦即結果中,可能百分八四機率會出現無交互作用之影響。當然,此處顯示之 p-值若要正確,基本上整個樣本之分佈必須獨立、常態分配並有固定的變異常數。
1 則留言:
您好:
感謝您撰寫了這個資源豐富的blog,它是我在學習的過程中遇到問題時的好幫手。
我目前需要做一個2*4的混合設計,組間變項兩組受試者人數不同,組內變項有四種條件。因為要在很多個clusters做類似的分析,所以想借重Matlab的迴圈功能。
請問MATLAB有辦法處理2way mixed-design ANOVA with unequal sample size的資料嗎?
另外,MATLAB中有檢定homogeneity of variance的函數嗎?若是homogeneity of variance的假定被違反的話,MATLAB可以提供校正的方法嗎?
非常感謝您。
張貼留言