11.12通用線性模式
11.12.1通化線適配Glmfit
常用線性迴歸 (generalized linear model)可以用於直線之適配或任何能與其參數構成線性之函數,其資料之取得假設為常態分佈。雖然這個方法並不十分實際,但仍然算是最簡單的迴歸方式。通用線性模式將線性模式加以擴充,其一是引入連結函數,使參數之線性可以放宽;其二是誤差分佈即使非常態分配的狀態也可使用。
B = glmfit(X, Y, 'distr')
B = glmfit(X, Y, 'distr', 'link', 'estdisp', offset, pwts, 'const')
[B,dev,stats] = glmfit(...)
通化線模 GLMFIT指令係以預測矩陣X及迴應值Y來配對,其採用的分配曲線由'distr'指定。執行結果置於B,是為估計之係數向量。 分配曲線'distr'可為 'normal'、 'binomial'、 'poisson'、 'gamma'與 'inverse gaussian'等。分配參數可適配至X中之各行,預設值是自行採用權威性連結。在大部份狀況下,Y為回應之量測值;二項式分配曲線中,Y為兩行資料,第一行為量測數目,第二行為試驗之數目(二項式中之N參數)。X之列數與Y相同,包括每一觀察點之預測值。
參數'link'亦提供選擇性連結,以此提供f(mu) = xb關係式之修正,使分配參數mu與預測子xb可以產生較佳的適配性。'link'可為下列情況中之一種:
文字串 :其內容及代表意義如下表:
| 'link' | 意義 | 預設連結 |
|---|---|---|
| 'identity' | μ=xb | 'normal' |
| 'log' | log(μ)=xb | 'poisson' |
| 'logit' | log(μ/(1-μ))=xb | 'bionomial' |
| 'probit' | norminv(μ)=xb | |
| 'comploglog' | log(-log(1-μ))=xb | |
| 'logloglink' | log(-log(μ))=xb | |
| 'reciprocal' | 1/μ=xb | 'gamma' |
| p(一個數字) | μp=xb | 'inverse gsussian'(p= -2) |
-一個細胞陣列的型式如 {@FL @FD @FI} ,此三函數分別定義該連結 (FL)、連結之導數 (FD)及反連結 (FI)。
- 一個細胞陣列的型式包括三個 inline 函數以定義連結、導數及反連結函數。
上述後兩項連結中,其細胞陣列可使用外加函數或以inline指令設定之三函數──連結、其導數及反函數。例如:
本函數: FL=inline('x.^-0.5')
導數函數: FD=inline('-0.5*x.^-1.5')
反函數: FI=inline('x.^-2')
然後在細胞陣列位置填入 {FL FD FI}
上述函數定義亦可改寫為: {@FL @FD @FI},只要將此三檔案定義在M-檔案中。或用匿函數如 FL=@(x) x.^-0.5
導數函數: FD=@(x) -0.5*x.^-1.5
反函數: FI=@(x) x.^-2
然後在細胞陣列位置填入 {FL FD FI}即可。
其他, 'estdisp'為離散參數之開關,設定為'on'時可使二項式或波義松分佈曲線之離散參數估計值( dispersion parameter)及標準差;設定為 'off' 時則使用理論離散值。對某些分配而言,'on'常為預設值。
輸入參數offset則是一個額外的預測向量,惟其係數固定為1.0。pwts則為先前權重之向量,例如每一對X與Y的觀察頻率。參數 'const'可為 'on' (預設值) 以包含常數項,常數項省略時則設定為 'off' 。常數項為B之第一元素(不要直接在X矩陣中的第一行輸入1)。
輸出方面,dev為正解之偏異值,stats則為統計資料結構,包括下面之欄位: stats.dfe (誤差之自由度)、 stats.s (理論與離散參數估計值), stats.sfit (離散參數估計值)、stats.estdisp(=1有離散估計值;=0固定)stats.beta(B係數之向量) stats.se (B係數之標準差), stats.coeffcorr (B相關係數矩陣), stats.t (B之t 檢驗)、 stats.p (B之p-值), stats.resid (殘值)、stats.residp (Pearson 殘值)、stats.residd (偏異殘值)、stats.resida (Anscombe殘值)。
範例:汽車之資料中,依重量由2100-4300磅的範圍有很多的選擇,可以進行加侖里程之檢測,設認為性能不佳者(poor)依抽測之結果有如下之數據:
w = (2100:200:4300)';
poor = [1 2 0 3 8 8 14 17 19 15 17 21]';
total = [48 42 31 34 31 21 23 23 21 16 17 21]';
[w poor total]
ans =
2100 1 48
2300 2 42
2500 0 31
2700 3 34
2900 8 31
3100 8 21
3300 14 23
3500 17 23
3700 19 21
3900 15 16
4100 17 17
4300 21 21
plot(w,poor./total,'ro')
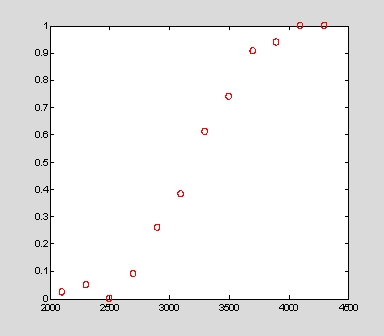
上述資料中,total為總抽測之數量;而 poor為認為性能不佳之數量。性能不佳之比例具有兩界限值,即[0 1]。可以利用這些資料進行適配分析,但一般線性迴歸無法包含兩個界限附近的數值,使用多項式或對數是一個方法。下面之例是利用'binomial'、 'logit'(預設)與使用'probit'進行適配比較:
[bl,dl, s1] = glmfit(w,[poor total],'binomial');
[bp,dp] = glmfit(w,[poor total],'binomial','probit');
[dl dp]
ans =
6.4842 7.5693
就偏異值而言,使用logit模式比probit為小。所以logit模式似乎略勝一疇。由上式的統計資料中,可以得知迴歸係數、標準差、t檢驗及P值分別如下:
[bl sl.se sl.t sl.p]
ans =
-13.3801 1.3940 -9.5986 0.0000
0.0042 0.0004 9.4474 0.0000
由於P值均接近於零,故其對應之截距與斜率均在顯著水準。
沒有留言:
張貼留言